Bagging vs Boosting in Machine Learning

Bagging and boosting are the most widely used ensemble learning methods. They are among the most effective model methods for achieving strong performance in research and practical systems.
Studies like A Case for Bagging and Boosting as Data Scientists’ Best Friends demonstrate that combining multiple models improves prediction accuracy and stability more effectively than relying on a single model. These techniques have become the standard practice of model building and implementation in data science. And they are widely adopted in machine learning communities because of this.
Bagging and boosting try to accomplish the same outcome, but they take entirely different approaches. Bagging is designed to reduce variance, and boosting is designed to decrease bias. Knowing how each method works and how to use each appropriately can be the difference between an adequate model and a high-performing model. Let’s understand the concept of ensemble learning with bagging and boosting.
In a Nutshell
Bagging and boosting are two powerful ensemble learning techniques that combine multiple models to improve the prediction accuracy. Bagging reduces variance and prevents overfitting by training models in parallel on random subsets. Boosting reduces bias by training models sequentially. A bank can use bagging to detect fraudulent transactions, while an e-commerce company may use boosting to predict customer dropout.
Understanding Ensemble Learning
Ensemble learning is a machine learning approach where multiple models are combined to solve the same problem, working together to produce better results than any one model could on its own.
This technique uses multiple individual models (also known as base learners) instead of relying on one algorithm. Taking only the strengths from each model, ensemble learning helps reduce errors caused by anomalies, bias, or variance.
There are chances that a single model may come across issues while overfitting or underfitting in case of complex requirements like classification, regression, and clustering. Overfitting is when your model knows the training data too well but struggles with anything new. Underfitting is when your model doesn’t learn enough from the dataset to make useful predictions.
To handle this issue, ensemble learning integrates multiple models having different strengths. As this approach improves model generalization, stability, and increases predictive performance, ensemble learning becomes the key technique in various AI applications such as fraud detection, medical diagnosis, and recommendation systems. Bagging and boosting are the two main techniques in ensemble learning. Let’s look into bagging and boosting in machine learning in detail.
What Is Bagging (Bootstrap Aggregating)
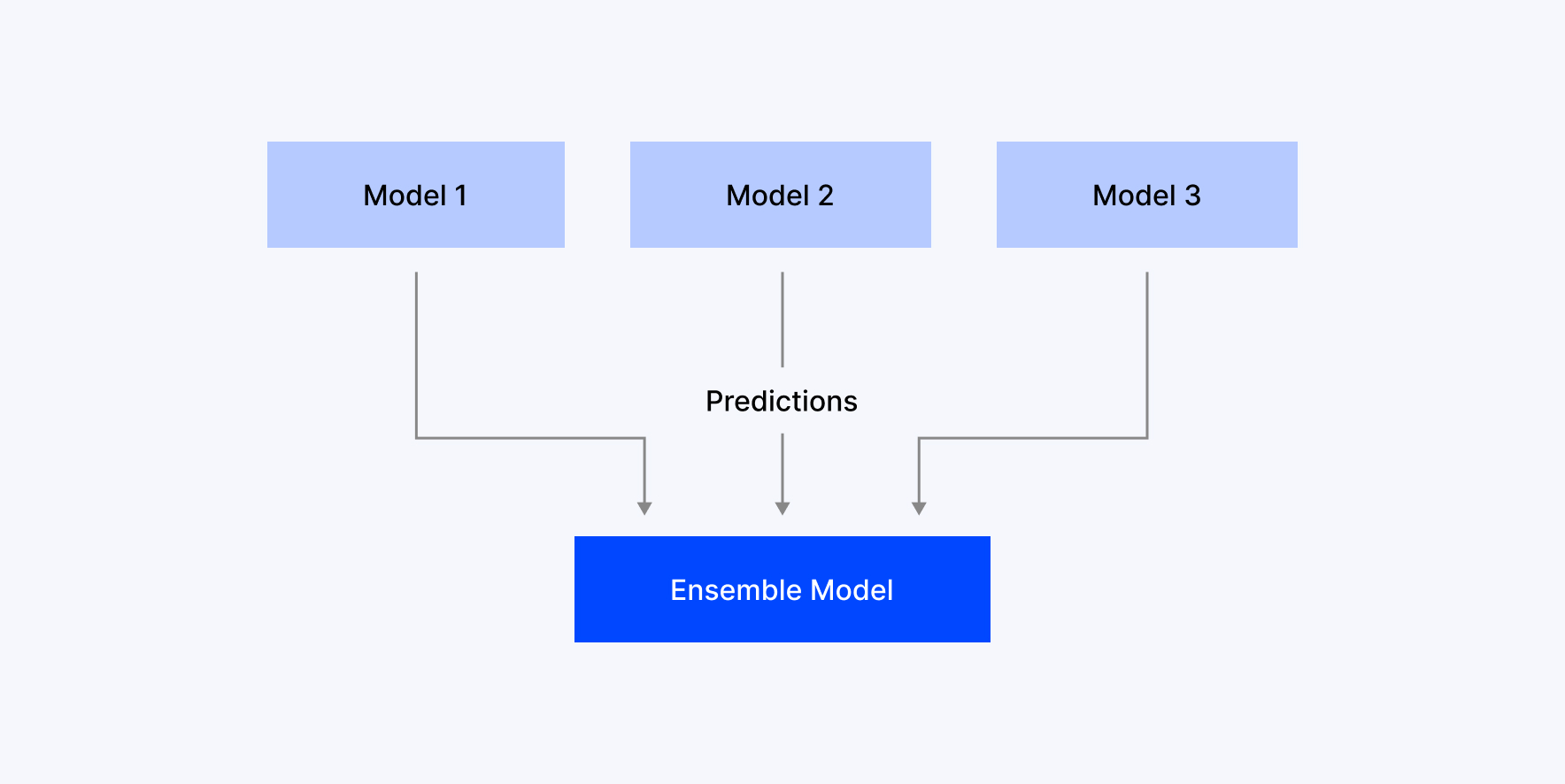
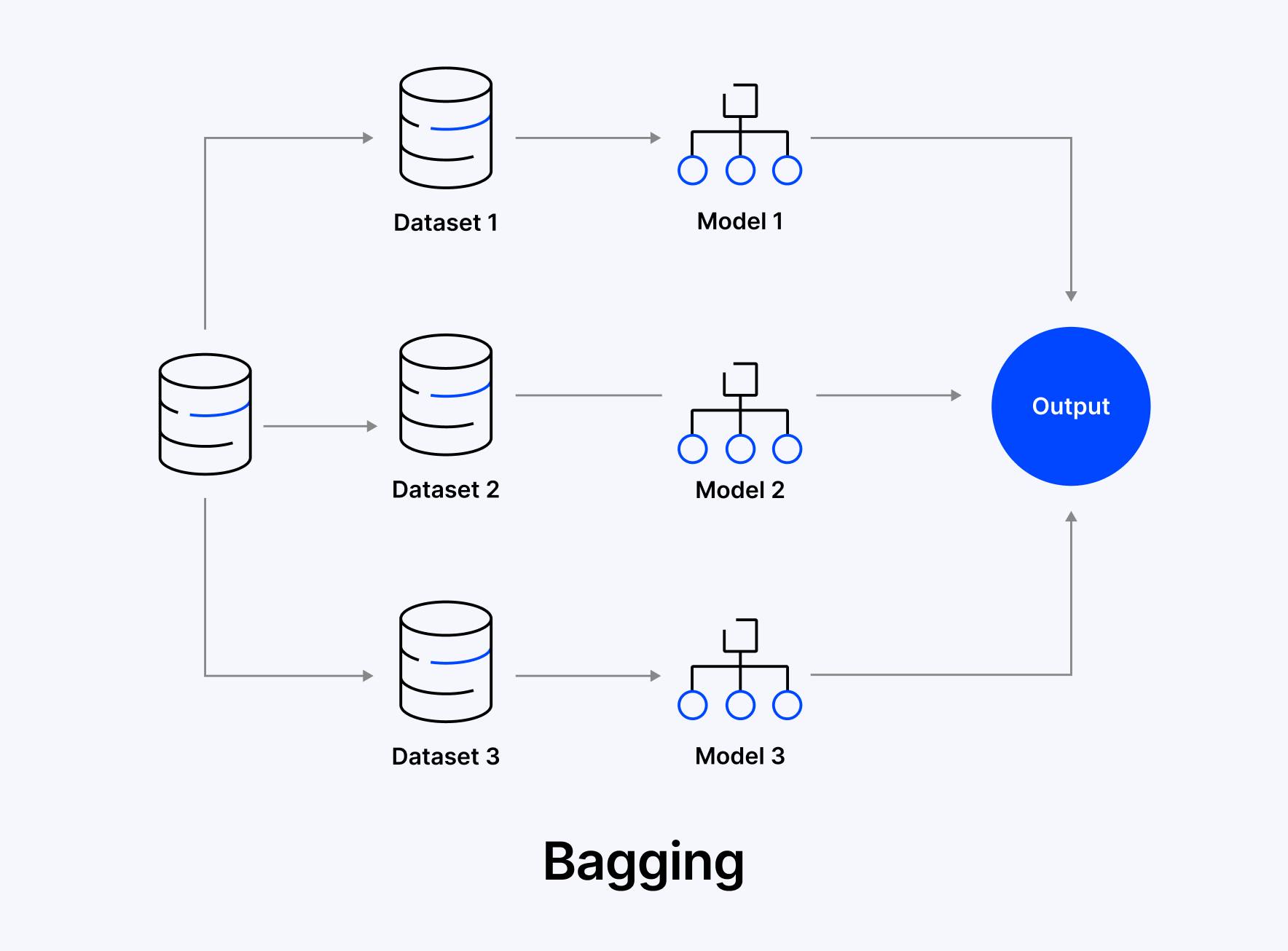
Bagging (Bootstrap Aggregating) is an ensemble learning technique that improves the performance and stability of models by training them on different random subsets of the dataset in parallel or individually, and combining their outputs.
Bagging helps us improve the accuracy of the model by reducing variance and preventing overfitting. This is achieved by creating several base model versions or decision trees, mostly which are trained on different bootstrapped subsets of the actual dataset. To generate these subsets, bagging uses random sampling with replacement.
After training in parallel, model predictions will be aggregated based on majority vote in case of classification tasks or by using regression tasks. In such cases where a single model may fail to give a reliable final prediction, this approach gives a more stable prediction.
For example, bagging is like asking a group of people the same question and taking the majority vote or average to get a more reliable answer.
There are three main steps in the bagging process.
- Initially, from the actual training data, it takes out various random samples with replacement.
- Next, independent training of a base learner takes place on each dataset.
- Finally, it combines the predictions from all learners, where classification models use voting, whereas regression models take the average.
Since bagging trains models on different subsets, it reduces noise sensitivity and helps generalize better, and hence, bagging becomes effective for high-variance algorithms such as Random Forest.
Benefits
- In complex models like decision trees, it helps to avoid overfitting.
- Gives more accurate predictions through Aggregation.
- Avoids data noise issues with random sampling.
- Bagging is applicable for parallel computing as models are trained independently.
Want to stabilize your model predictions with bagging?
Let's TalkLoading...
What Is Boosting?
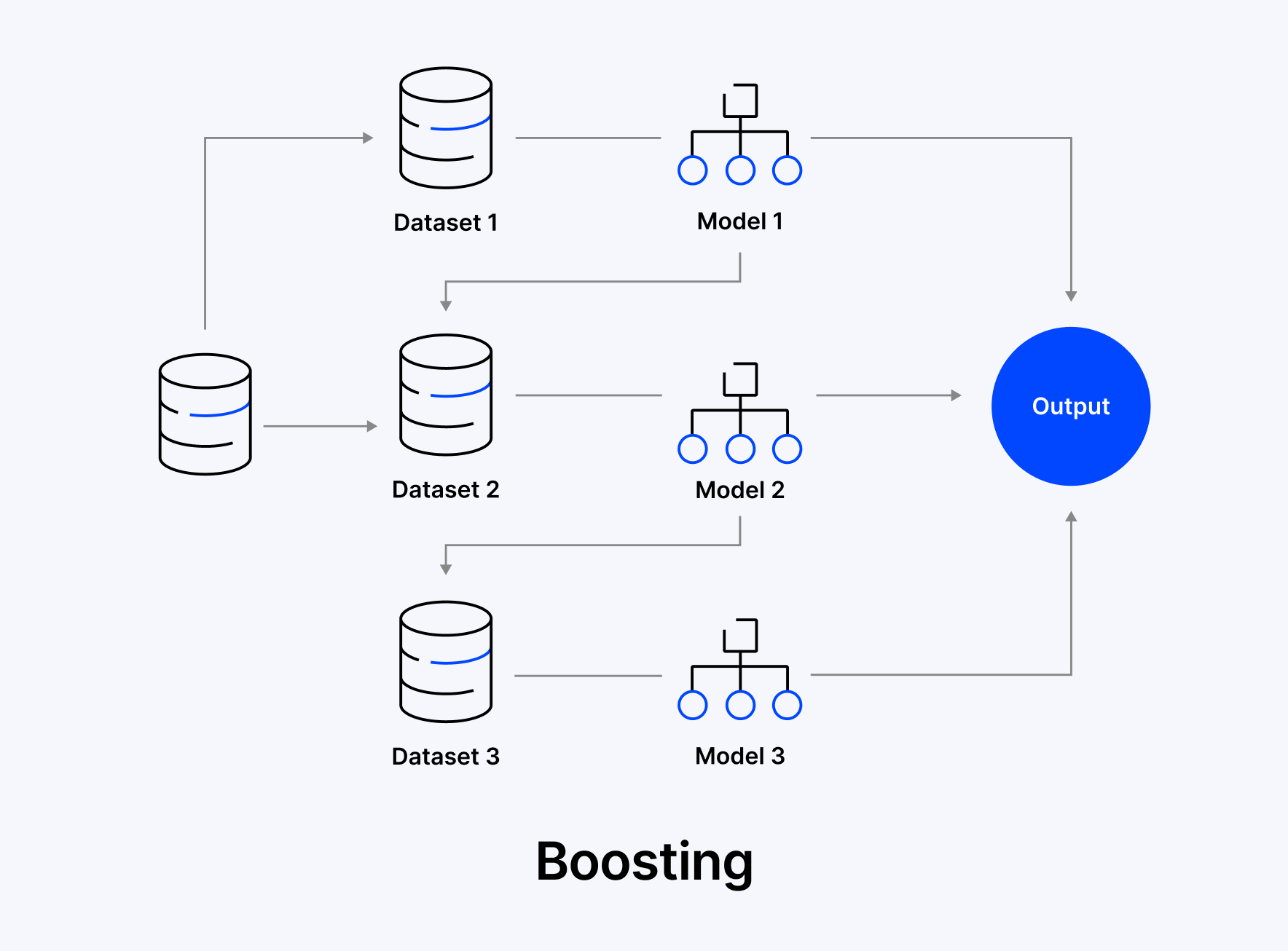
Boosting is a machine learning technique where multiple weak models, typically decision trees, are trained one after another, with each new model learning from the errors of the previous ones. Over time, this layered learning process creates a strong, highly accurate model.
For example, a team solving a problem step-by-step, learning from earlier errors to improve the final result.
As the first step, the first model is trained on the entire dataset. The second model is also trained on the same data, but gives more importance to the misclassified data points from the first model. This process goes on, with each model trying to correct the mistakes of its previous model. Finally, to make a single strong prediction, all models are combined, either by classification (weighted voting) or regression (weighted average).
Steps
- For all training samples, initialize the model with equal weights.
- Evaluate errors after training the first model.
- Identify the wrong points and increase weights.
- Update the data points and train the next model.
- Repeat updating data and training until errors are fixed.
- Combine model outputs based on weighted Classification (majority vote) or Regression (weighted sum).
Benefits
- For each single model, it improves accuracy.
- Without increasing variance, it reduces errors/bias.
- Works well for imbalanced data as well.
- Often achieves better results.
- Compatible with many weak learners, like decision trees.
Want to correct prediction errors step-by-step with boosting?
Let's talkLoading...
Similarities between Bagging and Boosting
‣ Both Are Ensemble Approaches
Both methods combine various models (base learners or weak learners) to create a stronger and accurate final model. Rather than depending on a single prediction model, these models aggregate all predictions from multiple models, which in turn results in better performance.
‣ Both Improve Model Performance
Increasing the accuracy and robustness of machine learning models is the primary goal of both bagging and boosting. They achieve this by reducing errors like variance (Bagging) and bias (Boosting). Therefore, the final model becomes more accurate and performs better when compared to individual models.
‣ Both Use Base Learners
The building blocks in both approaches are simple models, usually decision trees or weak learners. Although these base learners are not very strong individually, when combined through bagging or boosting, they produce a more powerful ensemble model.
‣ Both Are Versatile and Compatible
Starting from classification and regression tasks, bagging and boosting can be applied to a wide range of machine learning problems. To solve various real-world problems, these methods use different types of algorithms and datasets, which makes them versatile and compatible.
Difference between Bagging and Boosting in Machine Learning
| Aspect | Bagging | Boosting |
|---|---|---|
| Learning Approach | Parallel learning. Models are trained independently. | Sequential learning. Each model learns from the errors of the previous one. |
| Sampling Technique | Bootstrap Sampling. Random sampling with replacement. | Weighted Sampling. Focuses more on misclassified instances. |
| Error Handling | Learners are independent and do not consider past errors. | Each new learner corrects errors made by the previous ones. |
| Bias and Variance | Reduces variance, helps avoid overfitting. | Reduces bias, may reduce variance as well. |
| Sensitivity to Noise | Less sensitive to outliers and noise due to aggregation. | More sensitive to outliers and noise, as errors are weighted heavily. |
| Model Complexity | Typically, simpler models are combined (e.g., Decision Trees). | Builds progressively complex models. |
| Overfitting Tendency | Lower tendency to overfit. | Higher risk of overfitting if not tuned properly. |
| Performance | Performs well with high-variance models. | Generally delivers higher accuracy in many real-world scenarios. |
| Use Cases / Algorithms | Random Forest, Bagged Trees. | AdaBoost, Gradient Boosting, XGBoost, LightGBM. |
Challenges and Considerations
1. Increased Computational Cost
As Bagging and Boosting need to train multiple models instead of a single model, computational requirements and costs will also increase, particularly for complex base learners or large datasets. So, training and prediction times can be longer when compared to using individual models.
2. Overfitting in Boosting
Boosting can also lead to overfitting when the model focuses more on correcting errors, including noise errors, even though boosting often improves efficiency. Without proper techniques to avoid overfitting, boosting won’t be efficient if applied to small or noisy datasets. Overfitting means learning more and more from the training data, but with poor performance on real-world data. A very simple example of an overfitted model is a model that draws a zigzag line from data points instead of drawing a smooth curve.
Model Interpretability
The multiple models that an ensemble model combines behave as “black boxes”. As there are many weak learning models, it becomes difficult to understand how the final prediction is made. For sensitive applications like Healthcare, this is a drawback due to a lack of transparency.
Sensitivity to Noisy Data in Boosting
Boosting algorithms like AdaBoost give more importance to misclassified points. So, if these misclassifications are due to noise, the algorithm might increase errors instead of improving performance. When compared to bagging, this sensitivity makes boosting less reliable.
Conclusion
Bagging and boosting are two different ensemble methods that improve machine learning performance by combining multiple models, even though there is a significant difference in their approach and outcomes. Through parallel training on different data subsets, bagging reduces variance, and bagging is ideal for models like decision trees. On the other hand, boosting reduces bias by training models in sequence by correcting errors from the previous models with a very high accuracy, but with the risk of overfitting on noisy data.
When dealing with unstable models and noisy datasets, bagging is a safer choice for practitioners. If the data is relatively clean and you need an accurate model overall, go for the boosting method.
Deciding between the two methods completely depends on your problem, data characteristics, and balancing the two types of errors, like bias and variance. Variance will cause overfitting when the model is too complex and captures noise from the training dataset. Underfitting is the case where the model is so simple and skips important patterns. A good model will be the one that always finds the right balance to perform well on training data as well as with real-world data or unseen data.
Ensemble methods like Gradient Boosting, XGBoost, and stacking are improving fast and becoming more powerful, easier to understand, and are even better when working with deep learning workflows. Hence, these methods will be a key part of modern AI solutions.
At Webandcrafts (WAC), we help businesses unlock the full potential of Python and machine learning by building custom solutions, developing intelligent models, and managing the entire development pipeline, turning raw data into real, actionable results. Our experienced ML engineers ensure your machine learning workflows are efficient, scalable, and optimized for real-world performance.
Not sure if bagging or boosting suits your business?
Reach out to usLoading...
Discover Digital Transformation
Please feel free to share your thoughts and we can discuss it over a cup of tea.









