Spark Architecture - Everything You Need to Know

In the current data-driven economy, every business seeks solid solutions that can transform data into actionable insights and support informed strategic decision-making. The speed and volume of data being produced today require tools that can handle complexity quickly and efficiently. According to Statista, people created, captured, copied, and consumed a total of 149 zettabytes of data globally by 2024, with that number expected to grow beyond 394 zettabytes by 2028.
The explosive growth in data demands a level of understanding of the technologies that help organizations realize this potential. One of the major technologies is Spark, an open-source unified analytics engine for large-scale data processing.
Having an understanding of how Spark functions, along with its core components, helps everyone make informed decisions about technology investments, resource allocation, and aligning data initiatives with business strategy. This article explains the Spark's architecture, breaking down its core components and highlighting why Apache Spark has become essential in the world of big data.
In a Nutshell
Apache Spark is a strong open-source engine for large-scale data processing designed for speed, scalability, and versatility. It is ideal for handling complex big data workloads like batch processing, real-time streaming, machine learning, and graph analysis due to its in-memory computing, fault tolerance, and unified analytics capabilities. Spark is a building block in modern data analytics as it simplifies development by providing multiple language support and various cluster manager integrations.
What Is Apache Spark?
Apache Spark is a strong open-source engine for large-scale data processing designed for speed, scalability, and versatility. It uses in-memory caching and optimized query execution to enable fast analytic queries against data of any size. Spark emerged from the AMPLab at UC Berkeley in 2009 as a response to the performance limitations of the classic batch processing framework in Hadoop MapReduce in dealing with iterative algorithms and interactive analysis of data. Later in 2014, Spark was donated to the Apache Software Foundation, where it became one of the most actively developed big data projects.
Its relevance in big data processing originates from its ability to handle a wide range of workloads, including batch processing, real-time streaming analytics, machine learning, graph processing, and interactive queries with one framework. This made it a valuable tool for organizations facing a complex data challenge.
At the centre of the Apache Spark architecture is the driver-executor design, which allows for efficient distributed computing. This design allows multiple nodes to run concurrently, distribute data and computations across those nodes.
In contrast to a single-node computing architecture, being able to perform tasks in parallel will reduce the overall time taken to complete computations on large data sets.
In a single-node architecture, the process is more limited. You take a large task and divide it into subtasks, which are then completed sequentially.
In a distributed computing architecture, the fundamental principle is to take a large task and break it into smaller subtasks that all tasks can execute concurrently on a single node within the cluster. Capable of utilizing this distributed nature of computing is what allows Spark to scale and perform with the increasing demands from enterprise-level data in today's world.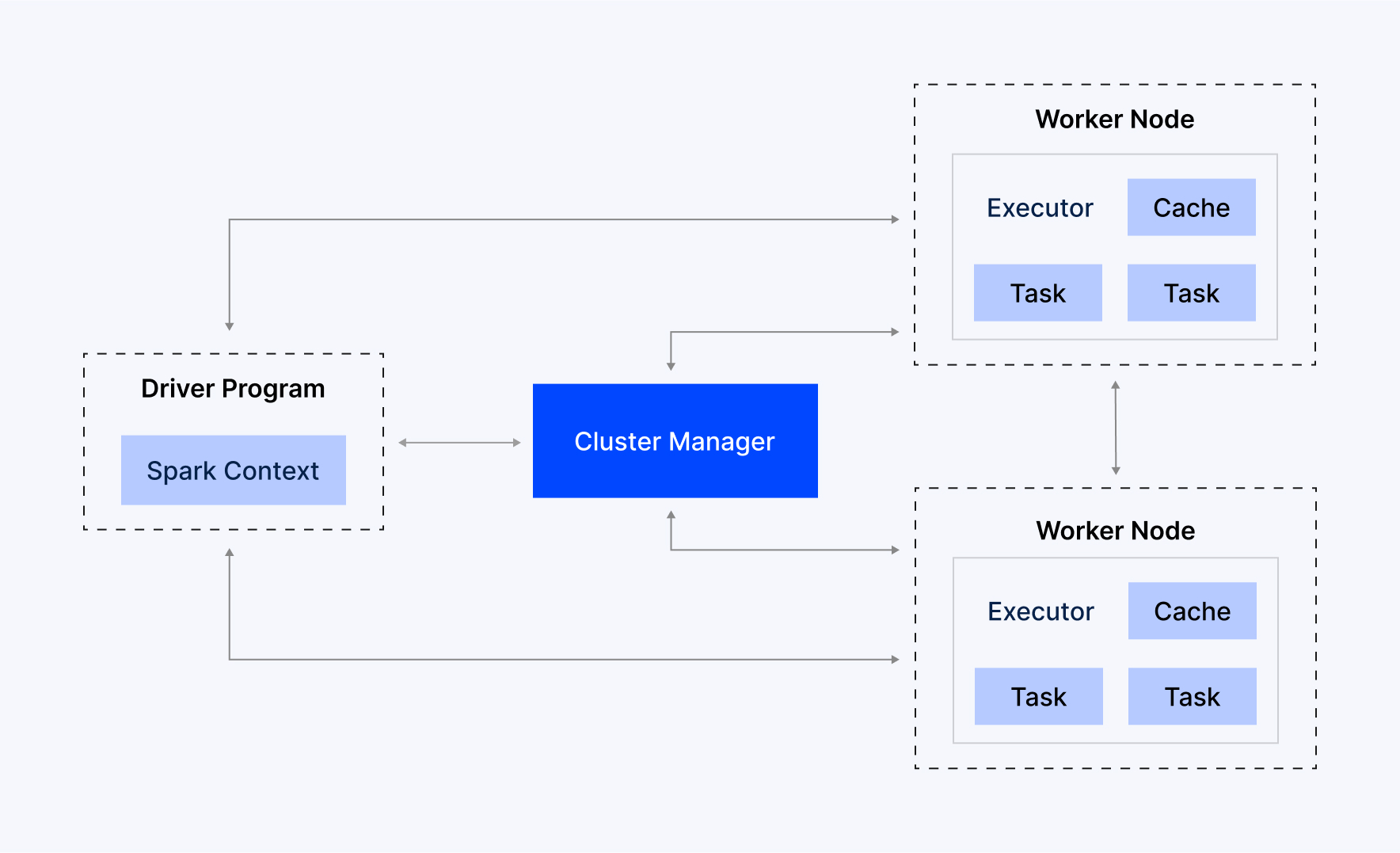
Key Features of Apache Spark
1. In-Memory Computing
One of Spark’s most powerful features is its ability to perform computations in memory, reducing reliance on disk I/O. This can significantly improve the processing speed, especially for iterative algorithms and interactive queries that require the same data to be accessed repeatedly. By keeping the data in RAM, Spark can run workloads up to 100 times faster than Hadoop MapReduce.
2. Unified Analytics
As Spark offers a unified and coherent approach to multiple data processing functions, you don't have to have a wide range of specific tools, which simplifies the development, deployment, and maintenance of complex data pipelines.
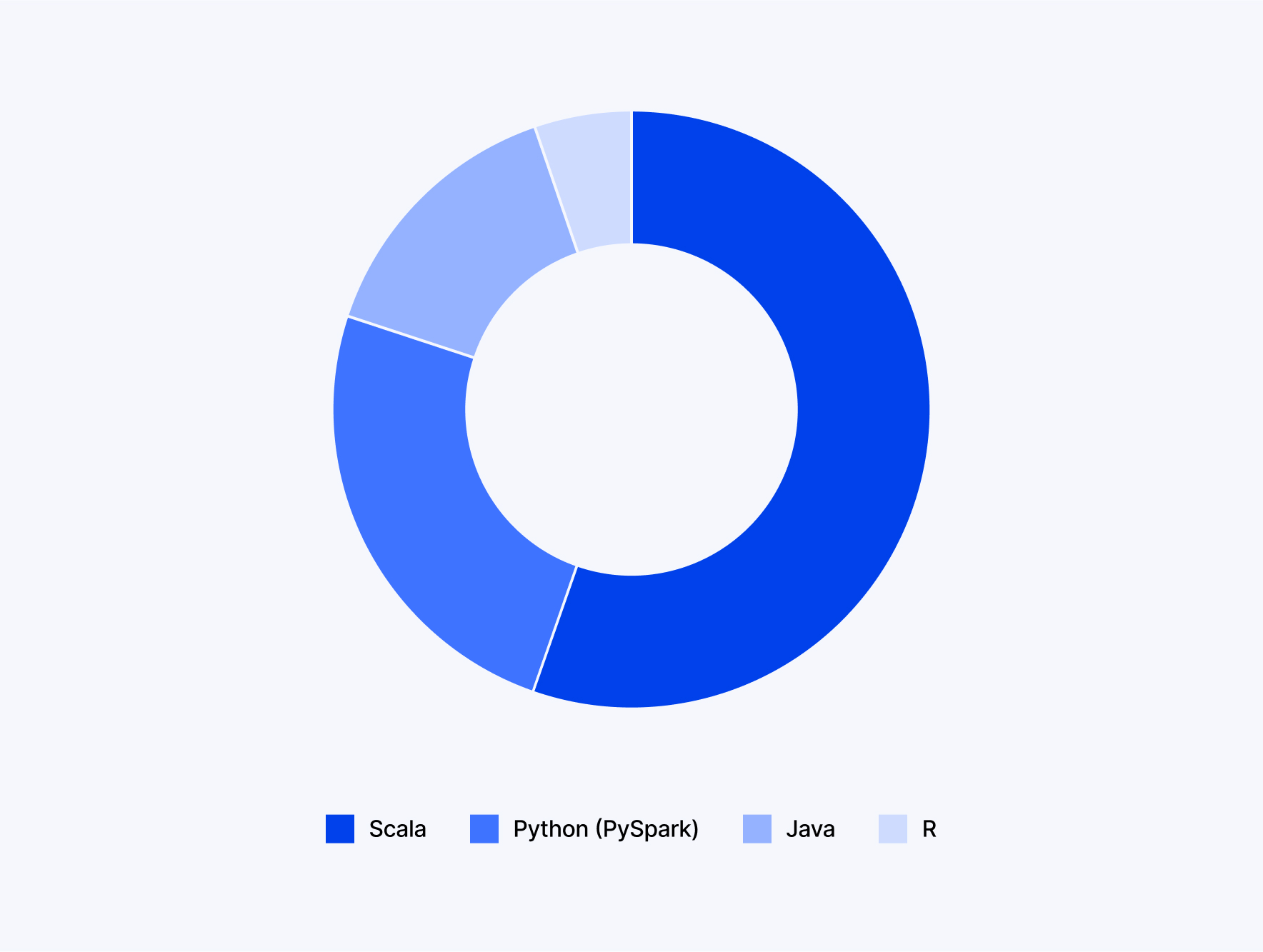
3. Support for Multiple Languages (Polyglot Programming)
Developers can interact with Spark using traditional programming languages such as Scala, Java, Python (PySpark), and R. This flexibility creates an easier way for teams with diverse developer skill sets to participate in the development process.
4. Built-in Libraries
Spark aligns with many high-level built-in libraries such as PySpark, Spark SQL, MLLib, Spark Streaming, and GraphX. PySpark provides a Python interface to Spark, Spark SQL allows users to query structured data efficiently, MLlib contains many machine learning algorithms, Spark Streaming processes real-time data, and GraphX performs graph-parallel computation. These libraries speed up the process of building applications and provide optimized implementations for many common data analytics use cases.
5. Fault Tolerance
Spark achieves fault tolerance through Resilient Distributed Datasets (RDDs). RDDs are immutable and can be recreated if a node fails. This gives a degree of fault tolerance to computations and can recover from failures without losing the data or restarting from scratch. This makes Spark very reliable for critical applications.
6. Lazy Evaluation
Spark uses lazy evaluation for transformations like map and filter, and they are not executed immediately. Instead, they are only recorded as a Directed Acyclic Graph (DAG) of operations. The actual computation does not occur until an action (such as collect or save) is invoked. Therefore, Spark can combine all operations and optimize the whole execution plan before executing it.
7. Advanced DAG Execution Engine
The advanced DAG scheduler is the heart of Spark, which plays a central role in task optimization. The DAG scheduler looks at the plan of transformations and actions, looks for the items that can be pipelined, looks for all the data shuffling that can be reduced, and also effectively eliminates unnecessary computations.
Key Components of Apache Spark Architecture
1. Driver Program
This is the central coordinator of a Spark application. The Driver Program can run on a node in the cluster (or just locally) and is responsible for defining the main method of the application, creating the SparkContext (the entry point to Spark functionality), and coordinating all the work to be done. The driver is responsible for translating the user's Spark code into several tasks, communicating with the Cluster Manager to get the resources it needs, and then assigning those tasks to the Executors for execution. It is also responsible for keeping track of the execution progress of tasks and the results.
2. Cluster Manager
The Cluster Manager is an external service that is responsible for acquiring resources in the cluster and allocating them for use by the Spark application. It is the resource negotiation authority for the cluster. Spark does not care about the type of Cluster Manager that it connects to. Spark can run with many options for a Cluster Manager, including:
- Standalone Cluster: The default simple cluster manager offered with Spark.
- Hadoop YARN (Yet Another Resource Negotiator): The resource manager of Hadoop, which is mostly used in business environments.
- Apache Mesos: A general-purpose cluster manager that can run Spark in addition to other types of distributed applications.
- Kubernetes: An increasingly popular container manager that Spark can use to manage resources.
3. Executors
Executors are distributed worker processes launched on Worker Nodes. Each Executor is used to perform computations (tasks) received from the Driver Program. The Executors keep all of the intermediate computation results, either in memory or on disk, and return the final results to the Driver. Each Executor also has its own cache for RDDs (Resilient Distributed Datasets), to optimize repeated computations.
4. Worker Nodes
Worker Nodes are the physical or virtual machines that will contain the Executor processes within the cluster. A Worker Node is a computational unit where Spark tasks are run. When Worker Nodes are started, they report their available resources (CPU cores, memory) to the Cluster Manager, and the Cluster Manager allocates them to application uses. Worker nodes host one or more of the Executors.
Modes of Execution
1. Cluster Mode
In Cluster mode, the Spark Driver Program executes inside the cluster and is managed by a Cluster Manager. This mode is recommended for all production deployments due to its fault tolerance and resource isolation. Once the client machine (where spark-submit is executed) submits the application and then disconnects, the Cluster Manager is responsible for starting the Driver on a worker node, where if the Driver fails, the Cluster Manager will restart it. Essentially, this mode supplies high availability and high certainty for long-running applications and helps to keep them robust.
2. Client Mode
In Client mode, the Spark Driver Program executes on the client machine. The Executors execute on the worker nodes within the cluster, but the Driver execution environment is outside of the cluster. This configuration can often be found during development and debugging, as the Developer can interact with their SparkContext and logs directly on the client machine. Similar to cluster mode, this mode is less fault-tolerant in production as the application will fail if the client machine goes down, so it cannot be used for production environments.
3. Local Mode
Local mode is meant primarily for development, testing, and debugging on a single machine. In local mode, the entire Spark application is run in a single Java Virtual Machine (JVM) on the local machine. The Driver and the Executors run in the same JVM. Local mode does not require a cluster manager and is most useful when working with small datasets or when testing the logic of a Spark application before deploying the application in a distributed cluster. Running production applications in local mode is not suitable due to their limited scalability and lack of fault tolerance.
Two Main Abstractions of Apache Spark
‣ Resilient Distributed Dataset (RDD)
RDDs are Spark's primary data abstraction, and collections of objects that are immutable, fault-tolerant, and can be processed in parallel. RDDs are "resilient" because they automatically recover from node failures. If one of the worker machines in Spark crashes and loses a piece of data (a partition of an RDD), Spark doesn’t need to reload everything from the beginning. Instead, it remembers how that piece of data was made (the steps it took), and just re-creates that missing piece of data using those steps.
RDDs are "distributed" because they are partitioned across the nodes in the cluster. RDDs support two types of operations:
- Transformations: These are operations that create a new RDD from an existing one (e.g., map, filter, union). Transformations are lazily evaluated.
- Actions: These are operations that execute the actual computation and either return a result to the Driver program or write it out to external storage (e.g., count, collect, saveAsTextFile).
‣ Directed Acyclic Graph (DAG)
When a Spark application has a sequence of transformations and an action, the Spark Driver builds a Directed Acyclic Graph (DAG) of operations. DAG is a representation of the RDD lineage (transformation path) and the steps of computation. In a DAG, nodes represent operations or RDDs/DataFrames, and edges represent the dependencies between them. The DAG is "acyclic" because there are no loops; the operation flows in only one direction. The DAG is built from the transformations applied to RDDs and shows the order in which each step should run. The DAG scheduler in Spark will use the DAG to optimize the execution plan by performing various operations, minimizing shuffles, and the order in which the operations are executed. This capability of optimization and how it is done has changed Spark's performance profile against other Big Data frameworks. This connection between RDDs, DAGs, and scheduling helps Spark run tasks in the right order and recover if something fails.
High-Level Abstractions: DataFrame and Dataset
RDDs are the core of Spark, but can be complicated and hard to optimize. To solve this, Spark added DataFrames and Datasets, which are built on RDDs for better performance and easier use.
A DataFrame is a distributed table kind of collection with named columns. It allows SQL-like queries and is optimized via Catalyst (Spark’s query optimization engine).
Dataset is a strongly typed collection combining RDD’s type safety (each element in the Dataset has a specific, predefined data type) with DataFrame performance, available in Java and Scala. Python users use DataFrames via PySpark.
Both DataFrame and Dataset use Spark’s Catalyst engine, support lazy evaluation, in-memory computing, and DAG execution.
Why use DataFrames and Datasets? Because they offer an easier and cleaner syntax compared to RDDs, run quickly with Spark’s Catalyst optimizer, and are well-suited for operating with structured data.
Thinking of implementing Spark at scale?
Let’s talkLoading...
What Are the Benefits of Apache Spark?
1. Speed up to 100x Faster than Hadoop
As noted, Apache Spark can be up to 100x faster than the traditional disk-based Hadoop MapReduce when running iterative algorithms and interactive queries. Spark's in-memory processing capabilities enable substantial speed-ups in these pipeline operations. This speed directly translates into faster insights, shorter training times for models, and more responsive data applications.
2. High-Level APIs in Java, Scala, Python, and R
User-friendly APIs in popular programming languages make it easier to build and manage data applications. This helps facilitate collaboration across diverse technical roles, data engineers will have an easier time, and data scientists will utilize their existing programming language skills to develop complex data processing and analytics applications more quickly.
3. Versatility
Since Spark is a unified analytics platform that supports multiple data processing paradigms, businesses need not deploy and manage separate systems for different data workloads, leading to less complicated architectures and reduced operational overhead.
4. Real-Time Processing
Spark Streaming provides real-time analytics on live data streams, which is critical for applications requiring rapid insights. These include real-time fraud detection, anomaly detection in IoT data, and other uses. Real-time processing gives organizations the ability to act immediately on events, gaining a competitive edge through rapid responsiveness.
5. Scalability and Fault Tolerance
Designed from scratch for horizontal scalability, capable of scaling across clusters with hundreds or thousands of nodes, and can process petabytes (1 petabyte could store over 200,000 HD movies) of data. RDD lineage and other natural fault tolerance properties enable applications to recover gracefully from failures, giving robust and reliable computation for critical enterprise applications.
6. Extensive Library Support
The Spark ecosystem of libraries is a key strength beyond the Spark core engine. Built-in libraries in Spark allow organizations to conduct non-trivial analytics or create rich data applications.
Cluster Managers in the Architecture of Spark
‣ Standalone Cluster
The stand-alone cluster manager is built into Spark and is easier to install and manage than other cluster managers. That is why it makes sense for smaller deployments, local development environments, and organizations that lack a Hadoop YARN or Mesos. Spark’s Standalone mode is easy to set up and is good for small jobs or trial runs. But it doesn’t include flexible resource sharing, support for several users, or detailed scheduling options. However, Spark is a realistic option for small, organized tasks or testing new ideas or concepts.
‣ Hadoop YARN (Yet Another Resource Negotiator)
YARN is generally the most popular and commonly used cluster manager in an enterprise Hadoop environment. YARN can centralize resource management and scheduling across all applications (e.g., Spark applications, MapReduce, Tez, etc), enabling the applications to share cluster resources more efficiently. YARN also includes advanced features like multi-tenant (multiple user) support, resource security and isolation, and Integration with Hadoop HDFS.
‣ Apache Mesos
Mesos is a flexible cluster management system designed to simplify resource allocation like CPU, memory, and storage across various machines, whether they're physical, virtual, or cloud-based. It helps developers build robust and scalable distributed applications.
Spark can run on Mesos as a first-class framework, allowing Spark to utilize Mesos' dynamic resource share capabilities. Mesos is known for its fine-grained resource allocation, High availability, and fault tolerance. Mesos is particularly effective in multi-tenant, heterogeneous environments, especially when running a mix of distributed applications with varying resource demands, such as Spark, Kafka, and Cassandra.
Conclusion
To maximize the benefits of Apache Spark and utilize the potential of big data for your organization, you need to understand the architecture that is built on the intelligent coordination of the Driver Program, Cluster Manager, Executors, RDDs, and a robust in-memory computation model that are all inherently designed for performance, scalability, and fault tolerance. The primary reasons Apache Spark is powerful are that it processes data in memory, has unified analytics, and a reliable fault tolerance mechanism, offering a flexible system that can handle both quick data tasks and heavy processing jobs.
The distributed nature of Spark and the advantages of execution optimization provided by the DAG engine make it extremely powerful, enabling enterprises to gain meaningful insights much faster than any other approach. As the complexity of data grows, so too will the importance of Spark in the big data ecosystem. The importance of Apache Spark goes beyond the transition from data collection for insight. It has triggered the ability to analyze, predict, and automate.
Webandcrafts (WAC) has deep domain expertise in designing and implementing reliable data analytics and AI/ML solutions. We engage in using sophisticated tools like Apache Spark to help enterprises turn data into a strategic asset.
Ready to transform your data architecture?
Let’s talkLoading...
Discover Digital Transformation
Please feel free to share your thoughts and we can discuss it over a cup of tea.









