Data Independence in DBMS: Key Types & Levels

Assume you want to make changes to your system, maybe upgrade some tools or shift to new technology, and everything just works. Your data stays right where it should be, no glitches, no need to rewrite things from scratch. That’s the kind of smooth experience data independence makes possible.
Data independence within Database Management Systems (DBMS) allows this flexibility in today's data-centric world. According to Harvard Business Review, poor data can impact any business badly.
A Database Management System organises and provides efficient access to data and forms the backbone of modern applications. Here, let’s understand how data independence in a DBMS can allow your business to thrive in a constantly changing digital environment.
What Is Data Independence?
Think of upgrading your smartphone without losing your apps or all of the data tied to those applications. While the phone underwent hardware and system software changes, your apps suddenly worked. This is similar to how data independence works in a DBMS. In this case, changes are made to the database structure or physical storage of a database without disturbing the way users and applications interact with the database.
So, what is data independence in DBMS? Data independence in DBMS is the ability to easily change one layer of a database engine, whether physical storage, logical structure (tables, relationships), or user views, without impacting other data systems.
This distinction is important because it separates data from application logic. Applications need consistent access to data, while businesses need to adapt to change (new infrastructure, storage technologies, data models, etc.). Without independent databases in a DBMS, changes can break applications or require costly downtime and rework.
A retail company upgrading its inventory database relies on the consistency of the data access in the sales app to retrieve the needed data. Still, it can also change the way that data is stored. This gives the company more options in choosing data storage procedures, saving time and money on application maintenance, and supporting scaling.
By emphasising independent databases in a DBMS, organisations take a posture of agility and are better able to create innovation without operational trouble. Even if you are just a business owner or doing it because it is your hobby/passion to play with technology, understanding this difference will provide the knowledge to build technical systems that will last because of their independence from each other.
Data Independence Types
Data independence in DBMS allows a degree of flexibility by permitting changes at one database level without influencing other database levels. The two types of data independence in DBMS are logical and physical. Each type serves different purposes.
Logical Data Independence
Logical data independence means the capability to change the logical schema (the structure of the database - tables, columns, relationships) without changing external views or the application programs that use or are based on the database. An external view is a means of representing a customized view of a database designed for a specific user or application. The external views identify the data the user needs to perform the intended task based on the underlying complexity in the database.
For example, suppose a company database has a table Employee (Name, Age, Department). Later, the database is changed to split this into two tables: Personal (Name, Age) and Work (Department Name). If external views are defined properly, a user querying employee information as before will not notice this change. The external view still presents the data as Employee (Name, Age, Department), and applications using that view do not need to be rewritten. This separation ensures flexibility and reduces maintenance efforts.
Physical Data Independence
In a DBMS, physical data independence means that any changes made to the physical storage of the database, such as how files are organized or indexed, do not affect the logical schema or any application programs. Physical data independence allows for changes to the way that data is stored while maintaining the same user-level data access mechanism through queries and views.
For example, consider a Student (ID, Name, Marks) table stored in a heap file (unordered records). Later, the DBMS administrator changes the storage to a B+ tree index on ID or moves the table to a different disk partition for faster access.
These internal changes in data storage or retrieval strategy do not affect SQL queries like SELECT * FROM Student WHERE ID = 101, which continues to work the same way. This separation enhances performance while keeping the database interface stable for users.
Difference between Physical and Logical Data Independence
Now, let’s differentiate between Physical and Logical data independence.
| Aspect | Logical Data Independence | Physical Data Independence |
|---|---|---|
| Definition | Ability to change the logical schema (e.g., tables, relationships) without affecting applications or views. | Ability to change physical storage (e.g., file structures, hardware) without impacting the logical schema. |
| Focus | Conceptual schema and user views. | Physical storage and access methods. |
| Example | Adding a new column to a customer table without updating the sales app. | Switching from HDD to SSD or changing indexing methods without altering application logic. |
| Impact | Applications and user interfaces remain unaffected by schema changes. | Logical schema and applications remain unaffected by storage changes. |
| Use Case | E-commerce platforms are updating data models for new features like discounts. | Retail chains are upgrading to cloud storage for scalability during peak seasons. |
| Complexity | More complex, as schema changes require careful mapping to views. | Less complex, as storage changes are typically transparent to applications. |
How DBMS Achieves Data Independence
Data independence is a crucial feature of Database Management Systems, especially for businesses that need to change database structure or data storage details without affecting their applications. But how can we accomplish data independence? Data models, schemas, metadata, and schema mapping are essential in designing and organising a database.
The structure of DBMS is built on a multi-tier architecture, including a physical level, logical level, and a view level; the physical level entails definitions of how data is stored (e.g., by file type), the rational level is the data schema (e.g., tables and relationships) that construct the database, and the view level is how end users or applications see or access the data.
Data independence can be attained when these three levels are separated. Data models (including hierarchical data models) provide a structure to define schemas and enable an organisation to define consistent naming conventions across levels of data abstraction. For example, a relational data model hosted in PostgreSQL defines data as tables and relationships, leaving specific storage details irrelevant.
Metadata, which is stored in the DBMS's data dictionary, describes the structure of the database, such as table definitions, indexing methods, etc. Schema mapping provides a bridge between layers and maps user queries from the view level into logical or physical level queries. This abstraction assures that changes made at one level do not compromise another. Oracle uses metadata to map logical schemas to physical storage, for example, so indexes can be changed or modified without changing individual queries.
You can see this in the commonly used DBMS on the market. In PostgreSQL, administrators can update table partitions for performance while keeping the same application logic, showing physical data independence in a DBMS. Likewise, Oracle gives users logical independence by enabling them to update the schema of tables independently with the views to which they have been provided access.
Assuming that we have a database for a university, and we have a table called STUDENT, which originally has columns - ID, Name, and Department. Then, a column, Date of Birth, is added. The existing applications that query that table still work and do not change at all. This is an example of logical data independence.
If the database administrator then took the STUDENT table and moved it to another faster disk or somehow changed how the data is stored internally, but left the structure of the table unchanged for the applications querying it, that is an example of physical data independence.
In this example, we provided a change in data structure or how data is stored, and users or applications access data consistently.
Curious how data independence can transform your business?
Let's TalkLoading...
Levels of Database
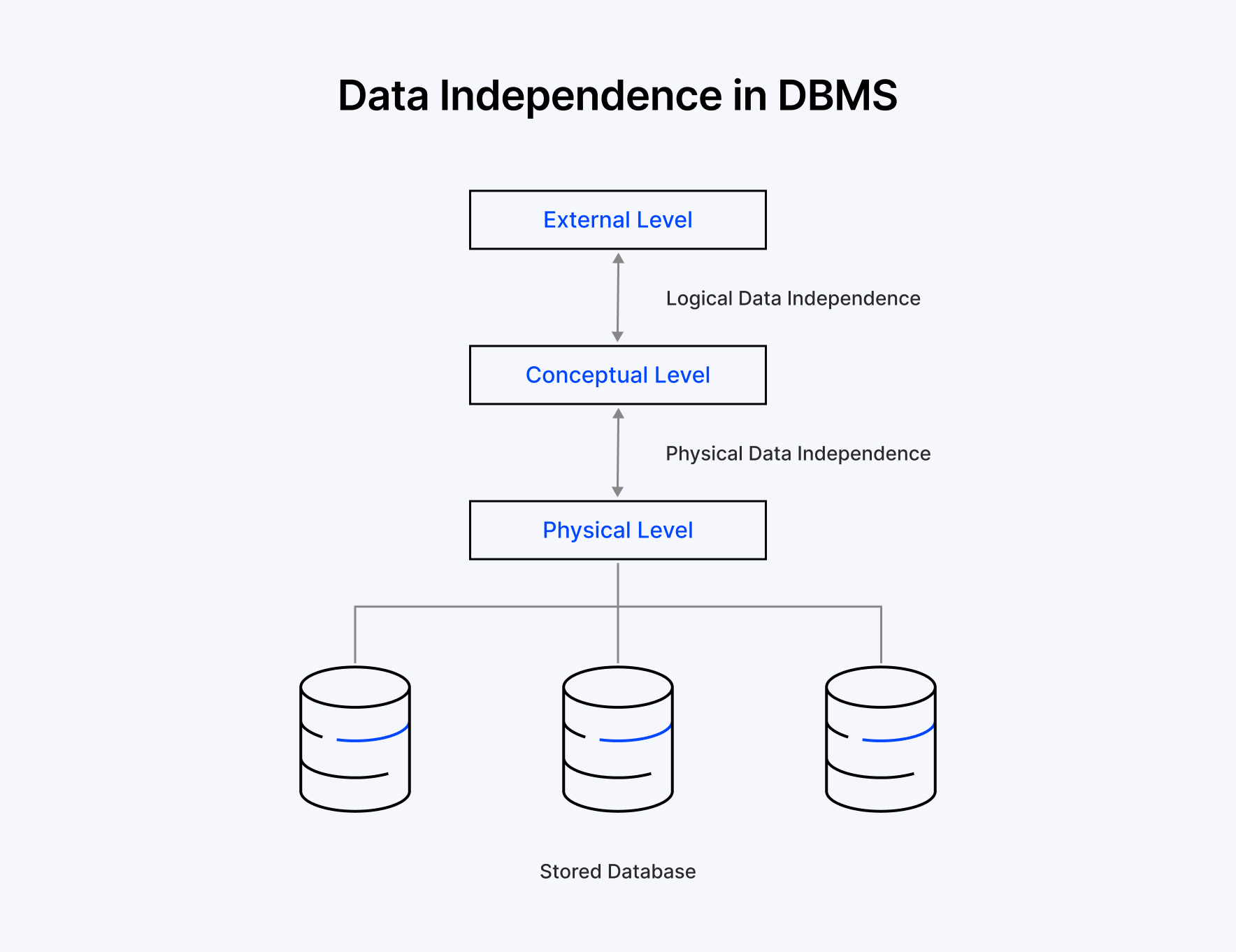
Physical Level: This is the bottom level that concerns data storage on hardware, file formats, indexing, and storage media (HDD vs SSD). A DBMS could implement B-Tree indexing to speed up searches, which would change how data is stored on disk. If changes occur here, like changing hardware storage from SSD to HDD, the other layers would not be affected, allowing physical data independence in a DBMS.
Conceptual Level: The conceptual level is the middle layer, providing a logical overview of the database as a whole (e.g., the tables, relationships, and constraints). It corresponds to a very general data structure, regardless of how it is stored and viewed in individual applications.
For example, we might define a "customer" table in a retail database with attributes such as name and ID number. If the schema needs to be updated, such as adding another column like birthdate, changing the conceptual schema does not affect applications that utilise the same data, allowing the DBMS to have logical data independence.
External Level: The external level is layer one and offers external database views to users or applications. Each user or application sees a subset of the data tailored to their needs. For example, the sales team might only know the customer's purchase history, while HR may only see employee information. Any changes made to the conceptual schema will not generally alter an external view at the user level, which allows for flexibility at the user level.
Summary
Data independence in a DBMS is fundamental to today's database systems, allowing organisations to function effectively in an ever-changing world. We discussed data independence in a DBMS, which refers to the ability to change any of the layers of the database (physical, logical, or external) without affecting applications.
The two types of data independence in a DBMS, logical and physical, allow changes to database schemas or storage devices without affecting the integrity of system data. Logical independence allows changing the schema, such as adding columns to tables. In contrast, physical autonomy allows for optimising shapes for storage media, such as swapping an old storage device with a more efficient one, like an SSD. This data independence is possible because of data models, schemas, and metadata, which permit easier change, scalability, improved security, and simultaneous access.
Adopting data independence in DBMS also puts organisations in a position to innovate and grow their organisation while being competitive in a data-driven world. If your company needs a complete, all-in-one digital solution, Webandcrafts can help. We are committed to creating development services that help businesses build custom data-driven, scalable, and robust web development projects based on your needs. Let WAC help you with your new digital transformation!
Ready to future-proof your database management system?
Reach out to usLoading...
Discover Digital Transformation
Please feel free to share your thoughts and we can discuss it over a cup of tea.









